用python如何进行数据分析 从入门到实践全流程 | 帆软九数云

在数字化时代,数据分析的重要性日益凸显。Python如何进行数据分析是众多行业从业者和学习者关注的焦点。Python作为一种强大的编程语言,因其简洁的语法和丰富的库,成为数据分析领域的首选工具。掌握Python数据分析,能够帮助企业更高效地提取数据价值,为决策提供有力支持。
一、准备工作:环境搭建与库的安装
要进行Python如何进行数据分析,首先需要搭建合适的开发环境。推荐使用Anaconda,它集成了Python解释器以及常用的数据分析库,省去了手动安装的麻烦。安装完成后,便可以开始导入必要的库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
这些库在后续的数据处理、可视化和建模过程中将发挥重要作用。
二、数据获取与读取
数据是Python如何进行数据分析的基础。数据的来源多种多样,常见的包括CSV/Excel文件、数据库、API接口以及网络爬虫等。以读取本地CSV文件为例:
df = pd.read_csv("data.csv", encoding="utf-8")
读取数据后,可以使用以下方法快速了解数据的结构:
df.head() # 前几行
df.info() # 列名、类型、缺失情况
df.describe() # 数值列统计特征
三、数据清洗与预处理
原始数据往往存在各种问题,如缺失值、异常值、重复值以及类型错误等。数据清洗与预处理是Python如何进行数据分析中至关重要的环节,它直接影响到后续分析结果的准确性。常用的数据清洗操作包括:
# 缺失值情况
df.isnull().sum()
# 简单删除缺失
df = df.dropna()
# 或者用前值填充
df.fillna(method="ffill", inplace=True)
# 去重
df.drop_duplicates(inplace=True)
# 类型转换(例如日期)
df["date"] = pd.to_datetime(df["date"])
四、数据处理与特征构造
在完成数据清洗后,可以利用Pandas进行更深入的数据处理和特征构造。这包括数据筛选、分组聚合以及创建新的特征列等。例如:
# 筛选
df_sub = df[df["value"] > 0]
# 新列
df["ratio"] = df["sales"] / df["quantity"]
# 分组聚合(如按支付方式统计订单数与金额)
grouped = df.groupby("Payment Method").agg({
"Order ID": "count",
"Order Amount": "sum"
}).sort_values("Order ID", ascending=False)
对于时间序列数据,可以进行按月统计等操作:
df.set_index("Order Date", inplace=True)
monthly = df.resample("M").agg({
"Order ID": "count",
"Order Amount": "sum"
})
五、探索性分析与可视化
探索性数据分析(EDA)是Python如何进行数据分析过程中不可或缺的一步。通过可视化手段,可以更直观地了解数据的分布、趋势和关系。常用的可视化图形包括:
# 单变量分布
sns.histplot(df["value"], kde=True)
plt.show()
# 折线图(时间序列)
df.plot(x="date", y="value")
plt.show()
# 散点图(看两个变量关系)
sns.scatterplot(data=df, x="feature1", y="feature2")
plt.show()
# 分组结果画图(例如 monthly)
monthly.plot(figsize=(10, 6))
plt.show()
六、简单建模
如果需要进行预测或分类等任务,可以使用scikit-learn库进行建模。以线性回归为例:
# 特征与标签
X = df[["feature1", "feature2"]]
y = df["target"]
# 划分训练 / 测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 建模
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
需要注意的是,建模前需要对数据进行适当的预处理,并选择合适的模型。对于初学者,建议先从简单的描述统计和可视化入手,逐步掌握建模技能。
七、用九数云BI玩转数据分析
企业在进行Python如何进行数据分析时,经常会遇到代码编写复杂、协作效率低等问题。九数云BI作为一款SAAS BI工具,能够有效解决这些痛点,帮助企业快速实现数据驱动。
数据整合与清洗
- **多源数据接入:**九数云支持多种数据源的接入,包括数据库、Excel、API等,方便用户整合企业内外部数据。
- **智能数据清洗:**九数云内置数据清洗功能,可以自动识别和处理缺失值、重复值等问题,提高数据质量。
可视化分析与探索
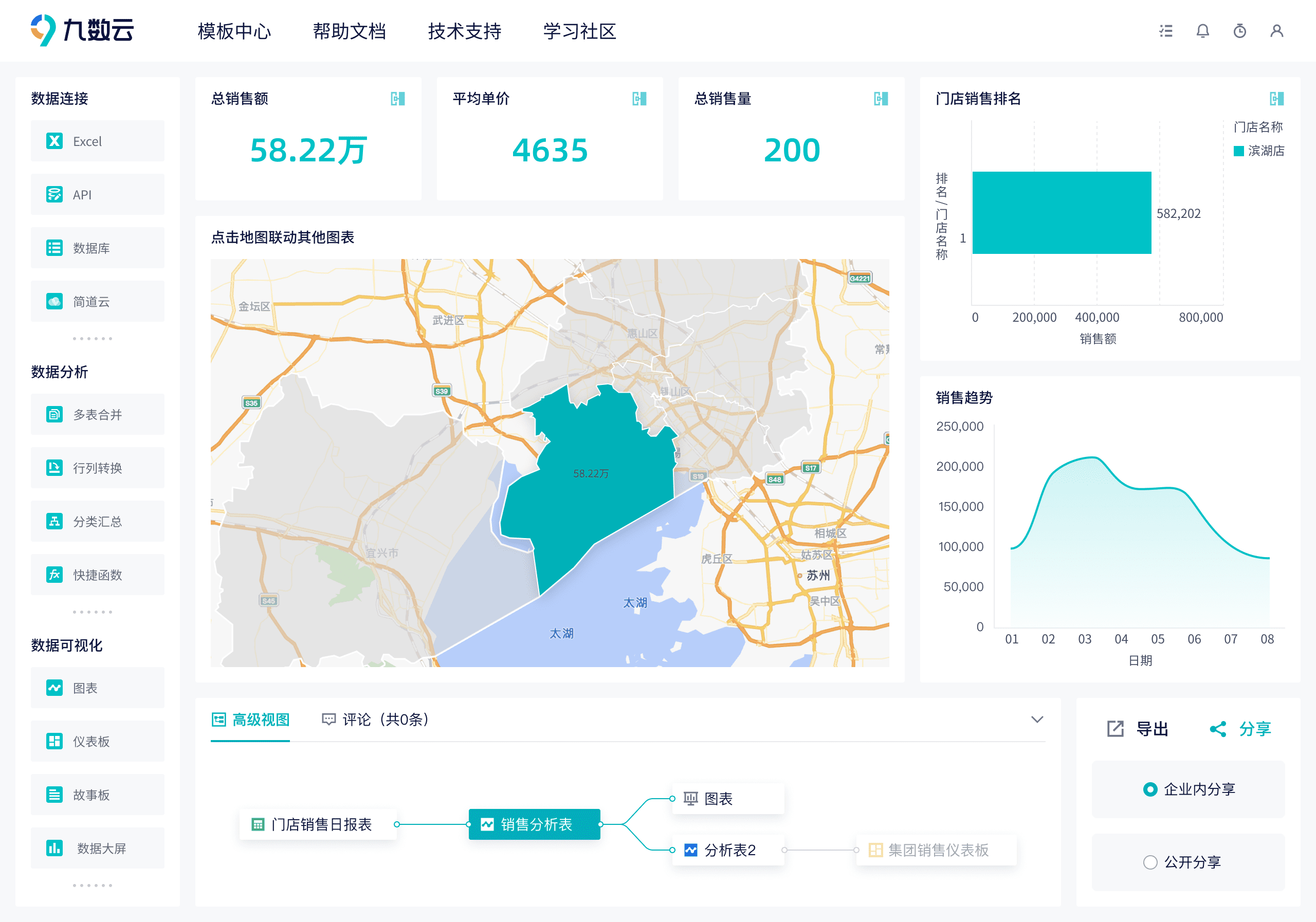
- **拖拽式操作:**九数云采用拖拽式操作,用户无需编写代码即可进行数据分析和可视化。
- **丰富的图表类型:**九数云提供多种图表类型,包括柱状图、折线图、饼图、地图等,满足不同场景的分析需求。
- **自定义仪表盘:**用户可以根据自己的需求创建自定义仪表盘,实时监控关键指标,发现潜在问题。
协作与分享
- **团队协作:**九数云支持团队协作,多个用户可以同时编辑和查看数据报表,提高工作效率。
- **权限管理:**九数云提供灵活的权限管理功能,可以控制不同用户对数据的访问权限,保障数据安全。
- **多种分享方式:**用户可以通过链接、邮件、嵌入等多种方式分享数据报表,方便与他人沟通和协作。

总结
Python如何进行数据分析是一个涉及多个环节的复杂过程,包括环境搭建、数据获取、数据清洗、数据处理、可视化以及建模等。通过掌握这些技能,可以从数据中提取有价值的信息,为决策提供支持。对于企业而言,借助九数云BI等工具,可以更高效地进行数据分析,实现数据驱动的业务增长。如果您想了解更多关于九数云BI的信息,可以访问九数云官网(www.jiushuyun.com),免费试用体验。

热门产品推荐


在Excel中,excel数据分档是指根据特定的条件或字段,将数据表格拆分成多个子表格或文件。例如,按照销售区域、部门、产品类别等进行分组,方便用户针对不同类别的数据进行分析和管理。通过excel数据分档,用户可以更清晰地了解数据的结构,快速定位所需信息,并进行有针对性的数据处理和分析。
九数云 | | 2025-12-19
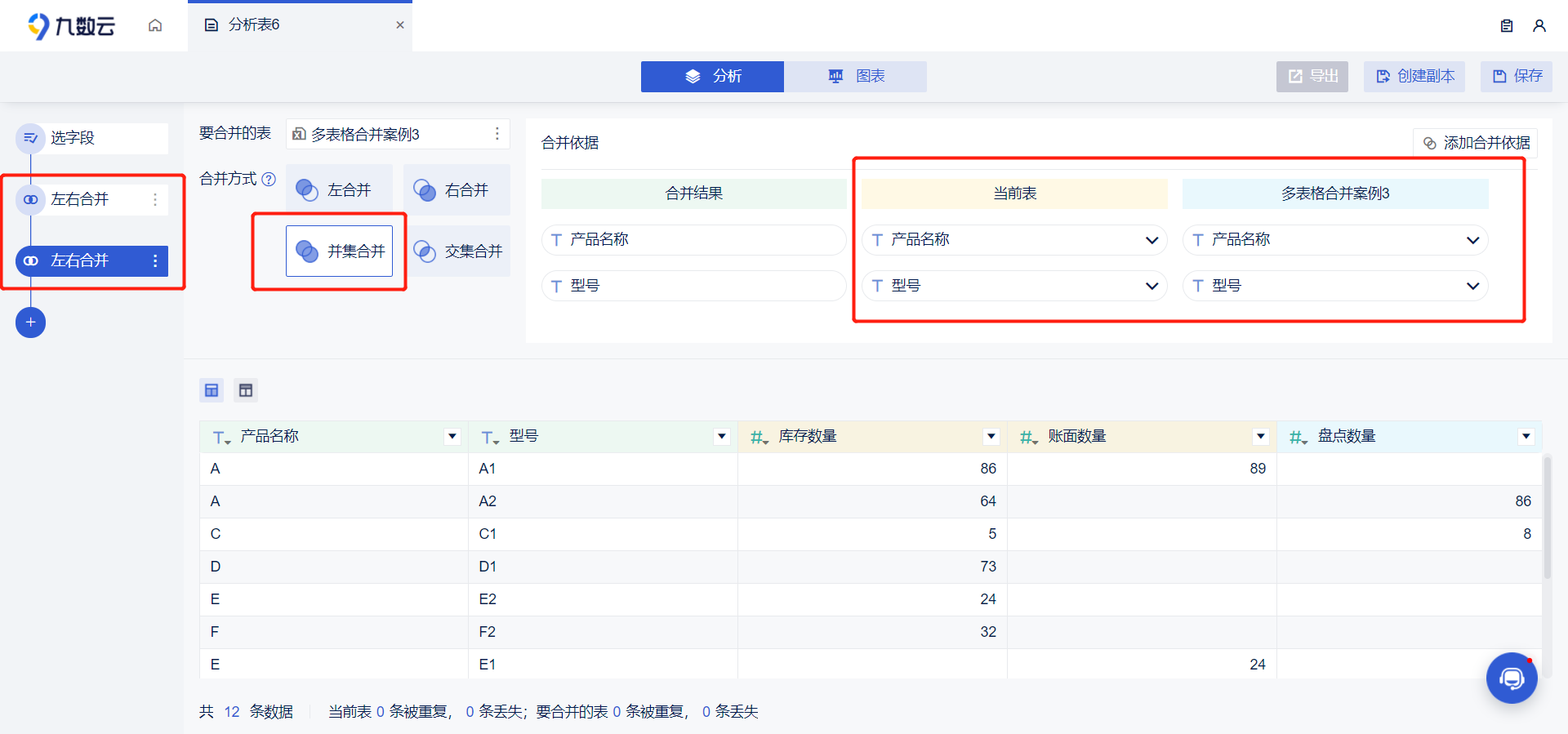
在日常工作中,我们经常需要处理大量数据,而这些数据往往分散在不同的Excel表格中。如何将这些表格快速、准确地合并成一个总表,进行统一分析,就成了提升工作效率的关键。本文将介绍四种高效的excel多表格合并方法,帮助您轻松搞定数据汇总,提升数据处理效率。
九数云 | | 2025-08-14
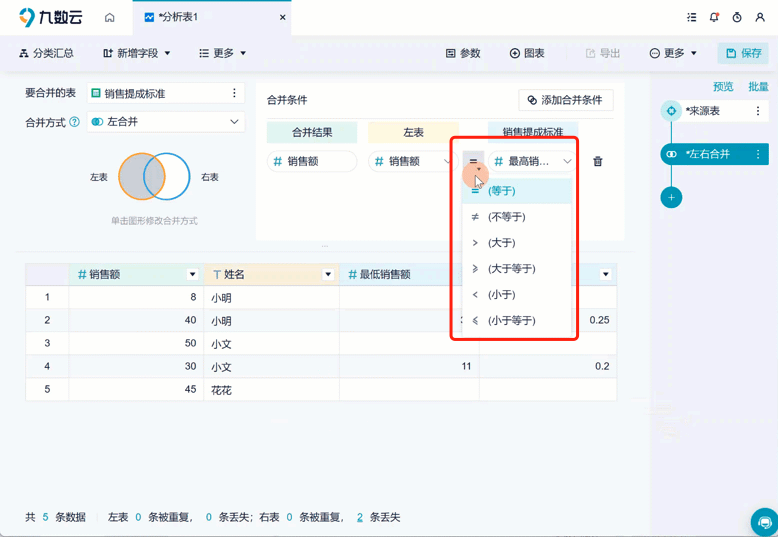
将分散在多个 Excel 文件中的数据整合到一起,是数据分析和报表制作中常见的需求。选择合适的多个excel合并工具,可以大幅提升工作效率。本文将深入探讨各种合并工具及其应用场景,助您快速上手,选择最适合自己的方法。
九数云 | | 2025-09-11
在数据分析领域,图表是不可或缺的工具。它们能将复杂的数字转化为直观的视觉形式,帮助人们更好地理解数据背后的含义。excel表生成图表功能强大且易于上手,无需专业的编程知识,即可轻松创建各种类型的图表,从而提升数据分析的效率和准确性。无论你是职场人士还是学生,掌握Excel图表生成技能都将让你受益匪浅。
九数云 | | 2025-12-16
掌握excel数据透视表怎么做,可以帮助你从繁杂的数据中快速提取有效信息,提升数据分析效率。本文将用清晰简洁的步骤,教你 5 分钟上手 Excel 数据透视表,轻松应对各类数据分析需求。
九数云 | | 2025-08-06
和小九一起学习excel表格变图表,可以展现数据魅力,提升你的工作效率!
九数云 | | 2023-08-15