AI数据处理:从数据采集到模型训练的全流程 | 帆软九数云

AI数据处理是指在人工智能和机器学习领域中,为了让算法能够更好地学习和预测,对原始数据进行一系列的转换和准备工作。这些工作包括数据采集、清洗、转换、以及特征工程等多个环节,最终目的是将原始数据转化为模型可以理解和有效利用的格式,从而提升模型的性能和准确性。有效的数据处理是构建高性能AI模型的基石,能够显著提升模型的训练效果和泛化能力。
一、数据采集与接入
数据采集是AI数据处理的第一步,其目的是获取构建AI模型所需的原始数据。数据来源多种多样,包括结构化数据、半结构化数据和非结构化数据。
- 结构化数据:通常存储在数据库表中,例如交易数据、用户数据、日志数据和传感器数据等。
- 半/非结构化数据:包括文本、图片、音视频、PDF文档和网页等。
常见的数据接入手段包括:
- API 抓取:通过应用程序接口获取数据。
- 消息队列:如Kafka,用于处理实时数据流。
- 埋点日志:在应用程序中嵌入代码以记录用户行为。
- ETL 工具:用于从不同来源提取、转换和加载数据。
- 爬虫:用于抓取网页数据。
二、数据清洗(数据质量)
数据清洗是AI数据处理中至关重要的环节,旨在提高数据的质量和可信度。核心目标是确保数据“干净、可信”,为后续的模型训练提供可靠的基础。数据清洗包括以下几个关键步骤:
- 缺失值处理:处理数据中的缺失值,可以采用删除、均值/中位数填充、插值或模型预测填充等方法。
- 异常值检测:识别并处理数据中的异常值,常用的方法包括箱线图、Z-score、聚类或孤立森林检测异常并修正或剔除。
- 去重:删除重复记录,确保数据集中没有重复的数据,保持主键唯一。
- 一致性修正:统一数据中的编码、单位和时间格式,例如将kg转换为g,将YYYY-MM-DD转换为MM/DD/YYYY。
- 噪声处理:对数据进行平滑、过滤或图像去噪等处理,以减少噪声干扰。
常用的数据清洗工具包括Python(Pandas)、SQL、分布式框架(Spark/Flink)和可视化数据准备工具。
三、数据整理与集成
数据整理与集成是将分散在不同来源的数据整合在一起,形成一个统一的、可用于分析和训练的数据集。这一步骤旨在将“散乱的多源数据”变成“可分析、可训练的统一表/样本集”。主要操作包括:
- 格式转换:将数据从一种格式转换为另一种格式,例如CSV↔Parquet,JSON↔表,以及统一时间/类别编码。
- 数据合并:通过主外键关联将不同表中的数据合并在一起,例如订单表 + 用户表,实现多源对齐。
- 分组与聚合:按照时间、用户、地区等进行分组,然后进行求和、均值、计数等聚合操作,为特征工程和报表准备数据。
- 数据采样/切分:将数据集拆分为训练集、验证集和测试集,采用分层抽样或时间切分等方法。
四、特征工程(Feature Engineering)
特征工程是AI数据处理中一个非常重要的环节,其目标是将“原始字段”转化为“对模型友好的特征”,从而提升模型的性能。特征工程包括以下几个方面:
- 特征转换:
- 数值化:将类别数据转换为数值数据,例如将“是/否”转换为1/0,将文本转换为ID/词向量。
- 标准化、归一化:使用Z-score、Min-Max、对数缩放等方法消除量纲差异。
- 离散化:将连续数据转换为离散数据,例如将年龄划分为“青年/中年/老年”,或使用分箱(bins)。
- 特征构造与组合:创建新的特征,例如交叉特征(如“城市*品类”)、统计特征(近7天平均值、最大值)、时序特征(趋势、周期)。
- 特征选择:
- 过滤法:使用相关系数、卡方检验、互信息等方法选择特征。
- 包装法:使用递归特征消除 (RFE) 等方法选择特征。
- 嵌入法:基于树模型/线性模型权重或神经网络内部表示选择特征。
五、数据标注与标签管理(监督学习场景)
在监督学习中,数据标注是必不可少的环节。数据标注的质量直接影响模型的性能。主要包括:
- 标注来源:人工标注平台、半自动标注(模型 + 人校验)、弱监督/远程监督等。
- 标签质量控制:多标注者投票、一致性检查、审计抽查等。
- 标签版本与溯源:记录生成规则、时间、使用模型,便于回滚与复现。
六、面向不同 AI 任务的数据处理要点
不同的AI任务对数据处理有不同的要求:
- 文本 / NLP:
- 分词、清除 HTML、去停用词、拼写修正。
- 子词/字节级编码(BPE、SentencePiece),构建词表或直接用预训练 tokenizer。
- 长文本切片、对话结构展开(role、turn 等)。
- 图像 / 视觉:
- 尺寸缩放、裁剪、归一化、颜色空间转换。
- 数据增强:翻转、旋转、随机裁剪、抖动等。
- 标注格式统一:分类标签、检测框、分割掩膜。
- 时序 / 日志:
- 缺失时间点填补、重采样(按分钟/小时/天)。
- 构造滞后特征、滚动窗口统计。
七、批处理、流处理与大规模数据
数据处理的方式取决于数据量和处理需求:
- 批处理:离线跑全量数据(典型:训练集构建),多用 Spark、分布式文件系统等。
- 流式 / 增量处理:只处理新到数据,如实时推荐、风控,常用 Flink/流式 ETL。
- 分布式计算:数据太大时用集群并行(Spark、Ray 等),避免单机内存瓶颈。
八、数据治理、隐私与合规
数据治理、隐私保护和合规性是AI数据处理中不可忽视的重要方面:
- 数据治理:质量指标、元数据管理、血缘追踪、访问控制等。
- 隐私保护:脱敏(脱标识化、泛化)、访问审计,必要时差分隐私或联邦学习等。
- 合规模型:明确数据用途和保留周期,符合本地法律与行业规范。
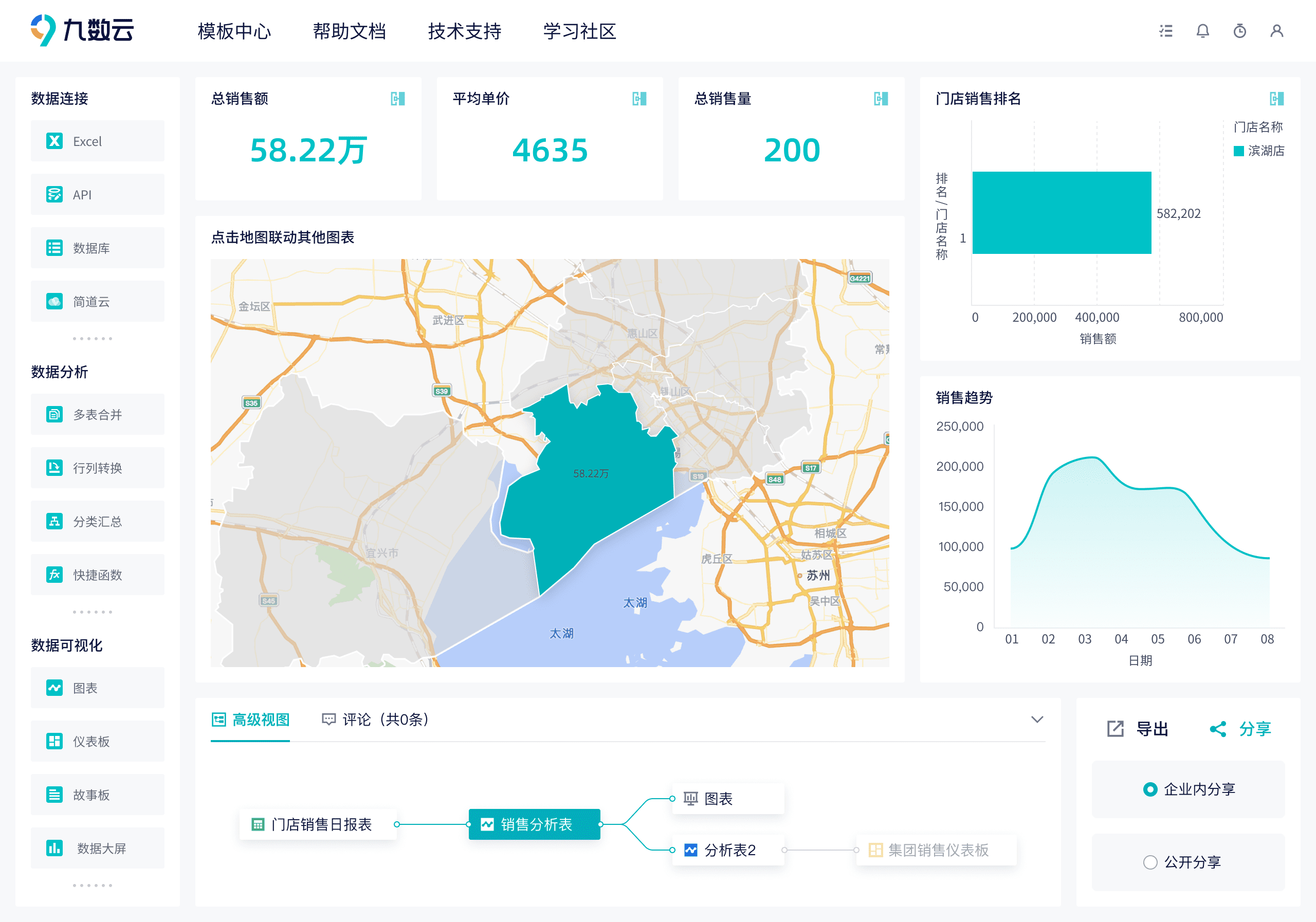
九、九数云BI:提升AI数据处理效率的利器
九数云BI作为高成长型企业首选的SAAS BI工具,在AI数据处理流程中扮演着重要角色。它不仅可以帮助企业高效地进行数据分析和可视化,还能简化数据准备流程,为AI模型的训练提供高质量的数据支持。通过九数云BI,企业可以更加便捷地整合、清洗和转换数据,从而加速AI应用的开发和部署。
九数云BI在AI数据处理中的功能与优势:
- 数据整合与接入:九数云BI支持多种数据源的接入,包括数据库、云服务、本地文件等,可以轻松整合来自不同渠道的数据,为AI模型提供全面的数据基础。
- 数据清洗与转换:九数云BI提供强大的数据清洗和转换功能,可以帮助用户快速识别和处理数据中的缺失值、异常值和重复数据,确保数据的准确性和一致性。
- 可视化数据探索:通过直观的可视化界面,用户可以深入探索数据,发现数据中的潜在模式和关联,为特征工程提供有价值的线索。
- 自动化数据准备:九数云BI支持自动化数据准备流程,可以大幅缩短数据准备时间,提高数据处理效率,让数据科学家和AI工程师能够更专注于模型训练和优化。
- 灵活的数据共享与协作:九数云BI支持数据共享和协作,团队成员可以共同参与数据处理和分析,提高工作效率和协作效果。

总结
AI数据处理是一个复杂而关键的过程,它直接影响着AI模型的性能和效果。从数据采集到模型训练,每一个环节都至关重要。通过有效的数据采集、清洗、整理、特征工程和标注,可以为AI模型提供高质量的数据基础,从而提升模型的准确性和泛化能力。九数云BI作为一款强大的SAAS BI工具,能够帮助企业简化数据处理流程,提高数据处理效率,加速AI应用的开发和部署。如果您想了解更多关于九数云BI的信息,可以访问九数云官网(www.jiushuyun.com),免费试用体验。

热门产品推荐


在信息爆炸的时代,数据如同一座巨大的金矿等待着人们去挖掘。而什么是大数据分析?它正是那把能够开启这座金矿的钥匙。通过系统地收集、存储、处理和分析海量、复杂的数据集,什么是大数据分析能够帮助我们发现隐藏在数据背后的有价值的趋势、模式和关联性,从而为决策和业务发展提供强有力的洞察。
九数云 | | 2025-09-04

九数云 | | 2026-07-16

九数云 | | 2026-07-01
在快节奏的商业环境中,每日报表怎么做至关重要。一份清晰、准确且及时的每日报表,能帮助企业管理者迅速了解当日运营状况,发现潜在问题,并做出明智决策。无论是销售业绩、生产进度,还是运营数据,每日报表怎么做都是企业高效运转的关键环节。
九数云 | | 2025-09-03
在数据分析的世界里,工具就像武器库。面对海量数据,你得先选对工具,才能事半功倍。今天我想结合自己多年的使用经验,给大家分享五大类数据分析工具,从最基础的 Excel 系,到高级编程工具,都有涵盖。无论你是刚入门的运营小白,还是想提升效率的数据分析师,这份指南都能帮你理清方向。
九数云 | | 2026-01-09
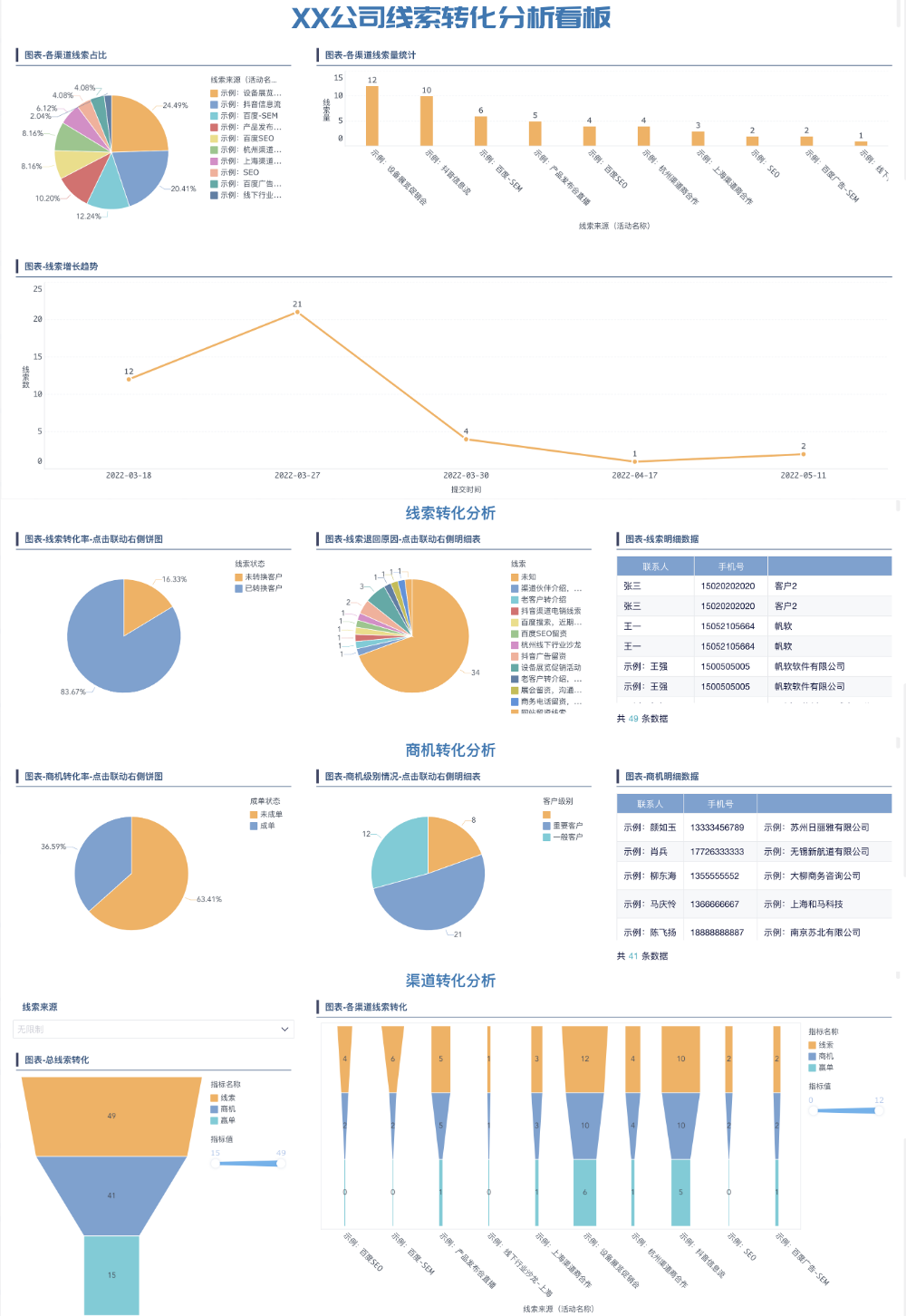
漏斗图适用于什么数据?漏斗图,又称倒三角形图,是一种形象地展示业务流程中数据逐级减少情况的可视化工具。它通过呈现流程各阶段的数量变化,帮助分析者快速识别瓶颈环节,优化转化路径。通过梯形宽度/面积表示环节差异和斜率显示减小率,支持自动计算转化率(每层相对于上一层或首层的百分比)。
九数云 | | 2025-12-24