主流开源BI工具有哪些?2026年推荐榜单 | 帆软九数云
 我敢打赌,你现在电脑里至少有5份Excel报表正等着“抢救”,而你真正缺的不是数据,而是一个让数据开口说话的翻译官。聊到主流开源BI工具,很多人下意识会去GitHub上狂搜Stars,却往往忽略了最关键的一点——开源的自由背后,往往隐藏着部署的繁琐和可视化的滞后。2025年已过大半,真正能在实战中留存下来的主流开源BI工具,比拼的不再是谁的代码更庞大,而是谁离业务更近,谁能让非技术人员真正跑起来。基于2025最新的技术生态与实战反馈,我将直接为你拆解当前最具竞争力的主流开源BI工具2025推荐榜单,帮你用最低的试错成本,找到最适合你的那一把数据利刃。 接下来,我们将深入剖析Apache Superset、Metabase、Grafana、DataEase、Redash这五款工具的适用边界与隐藏痛点,避免你投入大量部署成本却只得到一个没人用的空壳系统:1. Apache Superset 的大屏哲学与并发噩梦;2. Metabase 的极客美学与权限短板;3. Grafana 的监控王者与关系型数据的死穴;4. DataEase 的国产冲锋与长尾局限;5. Redash 的查询轻骑与维护断档风险。
我敢打赌,你现在电脑里至少有5份Excel报表正等着“抢救”,而你真正缺的不是数据,而是一个让数据开口说话的翻译官。聊到主流开源BI工具,很多人下意识会去GitHub上狂搜Stars,却往往忽略了最关键的一点——开源的自由背后,往往隐藏着部署的繁琐和可视化的滞后。2025年已过大半,真正能在实战中留存下来的主流开源BI工具,比拼的不再是谁的代码更庞大,而是谁离业务更近,谁能让非技术人员真正跑起来。基于2025最新的技术生态与实战反馈,我将直接为你拆解当前最具竞争力的主流开源BI工具2025推荐榜单,帮你用最低的试错成本,找到最适合你的那一把数据利刃。 接下来,我们将深入剖析Apache Superset、Metabase、Grafana、DataEase、Redash这五款工具的适用边界与隐藏痛点,避免你投入大量部署成本却只得到一个没人用的空壳系统:1. Apache Superset 的大屏哲学与并发噩梦;2. Metabase 的极客美学与权限短板;3. Grafana 的监控王者与关系型数据的死穴;4. DataEase 的国产冲锋与长尾局限;5. Redash 的查询轻骑与维护断档风险。
⚙️ 一、Apache Superset:功能庞杂的“航母”适不适合你的浅滩
🐍 1. 功能天花板的幻觉与真相
在讨论主流开源BI工具时,Apache Superset是绝对绕不开的巨无霸。作为一个由Airbnb贡献的顶级项目,它在2025年依然保持着极其旺盛的更新频率。它的核心优势在于对数据探索深度的极致挖掘——几乎可以说是目前开源界能买到的“航母级”数据分析平台。
如果你拥有一支技术储备极强的数据团队,Superset会让你感觉如鱼得水。它支持几乎市面上能见到的所有SQL数据库,通过SQL Lab让你直接编写复杂查询。但是,我们必须直击一个最让中小企业头疼的问题:可视化交互的滞后性。虽然Superset提供了丰富到令人眼花缭乱的图表库,但它的配置逻辑是面向工程师思维的,而非业务思维。很多时候,调一个复杂的桑基图或旭日图,你可能需要在几十个配置项中迷失。相比那些以易用性著称的SaaS BI工具,例如九数云BI的零代码拖拽逻辑,Superset对非技术用户的门槛在2025年依然没有被彻底解决。这导致很多企业花了几十万组建团队去维护它,但业务部门依然只在上面看一两张固定的表格,绝大多数复杂的可视化功能落灰了。
此外,权限管理虽然强大但极为生硬。当你要给数百家连锁门店分配只看本店数据的行级权限时,Superset需要你编写复杂的Jinja模板和SQL规则,这种体验在2025年追求极致效率的商业环境中显得格格不入。它的定位更像是一个开发者工具包,而不是一个完整的、开箱即用的商业智能解决方案。
⛰️ 2. 并发性能的隐秘深渊
很多技术选型者在看到Superset炫酷的Demo后,会毫不犹豫地在生产环境部署它,但随之而来的是密集的崩溃与投诉。Superset真正的性能陷阱在于高并发场景下的不稳定。2025年,随着微服务架构的普及,数据量爆发式增长,当多个用户同时尝试加载包含千万级数据背后的复杂图表时,如果底层的Celery队列和缓存策略没有优化到极致,整个看板会陷入漫长的转圈圈模式。
这种千万数据秒级处理的压力,对于像九数云这类SaaS BI工具而言,底层的列存优化和计算引擎已经帮用户屏蔽掉了,但在Superset中,你需要自己搞定ClickHouse或Druid的深度调优。这意味着,如果你是一家高成长型企业,业务数据量每个月都在翻倍,维护Superset的后端成本将会呈指数级上升。而且,一旦涉及到中国特色的数据源(如钉钉、简道云、金蝶云星空),Superset无法做到百余平台直连,你不得不额外编写ETL脚本去搬运数据,这无疑在数据链路中埋下了大量定时炸弹。在2025年的推荐榜单中,Superset依然是巨轮,但它只适合深海远航,在近海浅滩很容易搁浅。
💡 二、Metabase:极简美学的利与钝
💎 1. 业务人员的“第一杯可乐”
在众多主流开源BI工具中,Metabase以一种近乎禅意的极简姿态出现了。如果你让一个从未接触过数据分析的业务人员从零开始,Metabase绝对是上手最快的那一个。2025年的Metabase依然秉持着“让每个人都懂数据”的理念,它的提问(Question)模式是核心杀器。用户在界面上只需要点点按钮,不用写一行SQL,就能自动生成统计图表。
这种友好度极大地降低了数据分析的门槛。但是,这种易用性在复杂业务面前往往会迅速碰壁。Metabase拒绝提供那种花哨复杂的可视化样式,这让它在需要制作年度经营汇报、或者精细管理的BI看板时,显得非常“素”,甚至有些寒酸。在企业级应用中,缺乏行业分析模板是一个致命伤。用户往往需要从零去定义指标,而无法像九数云那样直接复用现成的电商运营模板或财务利润分析模板,这就导致分析思路经常卡壳——业务人员知道自己想看什么数字,但不知道如何科学地排布它们。
此外,Metabase的强项在于单表的快速查询,一旦涉及到多表关联、复杂的数据清洗和加工,它的轻量化架构就撑不住了。你只能依赖于数据库侧提前建好的宽表,任何临时的、需要脱敏、合并、计算字段的改动都变得极其痛苦。这让它更像一个数据展示层,而缺乏独立的数据处理能力。
⚔️ 2. 权限控制与治理的“半成品”困局
如果只是内部十几人的小团队使用,Metabase简直就是神兵利器。但把它作为公司级别的主流开源BI工具去推广,就会遭遇组织治理的滑铁卢。2025年,企业对数据安全的要求日益严苛。Metabase在精细化权限管控方面表现得很挣扎,它的权限颗粒度较粗,很难支撑起例如“A销售经理只能看华北区的数据,B经理只能看华南区,CEO看全国”这种典型的行政管理需求。
更让人头疼的是它的运维生态。虽然支持Docker一键部署,但后期的元数据备份、面板迁移以及自动化恢复极为不便。很多技术博客上调侃Metabase是“部署一时爽,迁移火葬场”。在协作层面,它缺乏和国内主流办公软件的深度打通。当看板出现异常,你无法直接在飞书或钉钉群中收到自动预警截图,依然需要靠人去点开链接检查,这种“离线感”在高节奏的商业竞争中非常危险。相比之下,九数云这类深耕国内的SaaS BI工具,早已实现了深度的IM集成,数据异常的秒级推送和协作,直接甩开了Metabase这类侧重欧美办公习惯的工具一个身位。
📊 三、Grafana:监控领域的偏科天才
🐙 1. 时序数据的绝对统治力
严格来说,Grafana在很多人眼里并不算传统的主流开源BI工具,它更像是一个运维监控平台。但在2025年的推荐榜单中,我必须给它留一个位置,因为它在特定领域做到了极致。Grafana对时序数据的处理能力是无与伦比的,如果你在做服务器监控、IoT设备传感器分析、应用性能追踪,它丰富的仪表盘插件和灵活的告警机制简直就是王者。
不过,如果你试图拿Grafana去分析公司的销售报表、财务利润甚至电商订单数据,灾难就开始了。Grafana的可视化逻辑是为了“发现问题”而非“发现规律”。它缺少做同比、环比、归因分析、联动下钻这些BI常规动作的便利性。拿最常见的饼图和矩树图来说,做出的效果只是为了看个大概,完全没有专业的数据看板的那种商业感。它也无法处理复杂的数据血缘追踪和业务指标管理。在2025年,很多企业误判了Grafana的应用边界,硬逼着运维工具去做经营分析,结果画虎不成反类犬。尽管Grafana近期在大力拓展数据源,增加了对更多关系型数据库的支持,但其核心绘图引擎对表格类分页、大数据量下的列过滤支持依然非常羸弱。这意味着,你如果想看一份长列表的明细数据,体验会瞬间回归Excel 2003时代。
🔌 2. 多源异构数据的连接短板
在现代企业的数据环境中,数据往往散落在淘宝、京东、抖音等电商平台以及简道云、金蝶等业务系统中。Grafana的核心是插件化,虽然社区提供了海量插件,但多数质量参差不齐,缺乏官方主流认证。特别是针对国内互联网平台的数据源,Grafana几乎处于断连状态。
你无法通过简单配置就拉取抖音电商的订单明细,也无法直连云仓的库存流水。想要在Grafana上拼凑出完整的经营全貌,你必须在后端搭建一整套Kafka或Flink流处理管道,将业务数据强行转换成时序指标格式。这种为了迎合工具而扭曲业务数据的做法,本质上违背了BI工具的初衷。而且,Grafana的零代码能力仅限于可视化配置,在数据建模阶段,依然是SQL和脚本的天下。所以,Grafana只能是你的技术监控看板,如果要构建企业级的一套完整BI看板体系,单靠它必然会导致数据链路割裂。
🚀 四、DataEase:国产冲锋的骄傲与代价
⏱️ 1. 本地化部署的极致性价比
谈及2025年的主流开源BI工具,DataEase绝对是国产开源界的现象级产品。它主打“人人可用”,一经发布就迅速在GitHub上斩获大量Star。DataEase最大的亮点在于极强的一体化部署能力和美观的模板风格。如果你需要一个开箱即用,且安装过程完全傻瓜化的工具,DataEase的安装包体验是最好的。
它解决了Superset和Metabase在国内场景下的很多水土不服问题,比如内置了常见的数据源驱动,图表效果也非常契合中国式报表的审美——边框、阴影、配色看起来都很有大厂范儿。作为一款新兴的开源产品,DataEase的迭代速度很快,社区响应也很积极。但是,对于一个正在狂奔的高成长型企业来说,开源工具最怕的并不是功能少,而是系统底层的稳定性隐患。DataEase在处理千万行数据秒级处理这类高压场景时,时常会出现渲染卡顿和内存溢出。它对于多维度交叉分析下的计算优化依然不够成熟,很多时候你等了半分钟,等来的可能是一个空洞报错。这对于习惯了秒级响应的现代业务人员来说,是难以容忍的。且在权限体系上,虽然比Metabase完善,但相比成熟的企业级方案,依然缺乏那种无孔不入的字段级脱敏和细致的角色矩阵。
🛞 2. 重装与轻用的博弈
DataEase试图做得很重,比如加入了仪表板市场、数据填报等重功能,这种“全家桶”策略颇受部分传统企业喜欢。但随之带来的问题是运维成本的反噬。虽然号称开源免费,但在实际生产环境中,为了保证性能不崩溃,你往往需要给它配置较高的服务器资源,甚至还需要专人去维护。另外,DataEase目前的生态连接还有极大的提升空间。在与简道云、金蝶云这样细分领域的国民级应用直连时,依然需要繁琐的中间库,无法实现真正的无痛打通。
而且在复杂的跨数据库关联分析中,DataEase留给数据的计算缓冲较小,容易出现一对多关联时的数据膨胀错误。很多电商企业在用DataEase去做多店铺利润分析汇总时,经常发现自己还要额外用Excel去手动平账,这使得所谓的“数据决策”链条并没有真正闭环。在2025年,DataEase依然是值得尊重的挑战者,但更适合那些预算有限、业务比较简单的IT团队去试水,若要用它扛起整个公司的数字化转型大旗,还需时日沉淀。
🧲 五、Redash:滞留在时光里的查询轻骑兵
🥶 1. 低代码查询的老牌情怀
Redash在早期的主流开源BI工具2025推荐榜单中,其实是很多初创团队的首选。它的设计哲学极其直接:专注于SQL查询并将结果可视化。如果你团队里全是SQL高手,不喜欢拖拽,只想在网页上写代码并分享URL,Redash简直是梦中情工具。2025年Redash依然活得好好的,因为简单,所以可靠。
但是,简单在这里也是一个双刃剑。Redash在2025年的复盘审视下,它的重心依然停留在“查询结果”上,而非“数据分析”。它不支持丰富的交互式下钻分析,没有像样的仪表板布局能力,图表样式也还保持着5年前的复古设计。在大屏可视化需求旺盛的今天,Redash所能提供的展示效果,往往很难说服老板这是一份专业的报告。最关键的一点,这个开源项目近两年发展相对迟缓,被收购后社区活力大不如前,兼容性和新特性的支持往往慢人一步。你会发现在Redash里做任何稍微复杂的图表联动,比如点击柱状图筛选表格数据,都需要打断的变身写代码。看着其它工具灵活的多维联动,Redash显得有些力不从心。
🔗 2. 缺乏纵深与业务贴合度
在2025年,企业需要的不仅仅是看数,而是能够打通数据全链路的数据分析平台。Redash无法直连纷繁复杂的业务系统,也没有模板市场为你提供分析思路。你只能靠自己硬闯。虽然它支持API获取数据,但在应对电商平台需要每小时刷新一次推广计划数据,或者连锁门店需要实时盘点库存变动时,它就完全没法胜任了。缺乏自动化的任务调度和预警,让Redash彻底沦为被动看数工具。
对于需要构建系统化数据决策体系的团队来说,Redash更像是一个辅助的SQL收藏夹,而非一个完整形态的BI看板解决方案。本质上,它没有帮助企业沉淀分析资产,所有的看板和查询都是散落在个人账户下,难以从组织角度去做统一的管理和复用。这样的定位,使其在2025年主流BI的复杂战局中,逐渐掉出了第一梯队。
💨 六、跨过量体裁衣:破除开源泥潭的破局者
🛠️ 1. 从工具思维到场景思维的跃迁
盘点完以上的主流开源BI工具2025推荐榜单,你可能会发现一个残酷真相:似乎没有哪个是完美的。巨头如Superset太难驾驭,轻量如Metabase无法深入管理,监控如Grafana偏科严重,国产如DataEase还在成长,而Redash已呈现老态。这并不是你选型能力的缺失,而是开源生态天然的局限。开源工具提供的往往是一个“半成品”的操作台,需要你从头去搭建工艺、设计流程。而2025年的商业环境,留给企业的试错窗口期已经极度压缩。
作为帆软旗下深耕SaaS BI领域的九数云,它其实代表了2025年BI工具发展的重要方向——跳过造轮子的泥潭,直接进入业务场景。相比于上述开源工具,九数云最大的差异化在于它真正实现了从数据获取到分析决策的闭环。你不再需要自己去配置复杂的数据源驱动,因为它能像水龙头一样直连上百种主流平台;你不再需要编写复杂的SQL去构建宽表,因为零代码拖拽就可以在几毫秒内完成千万条数据的筛选与透视;你也不再需要从零开始设计看板,因为它配载了200多个深度贴合行业的分析模板,简单替换数据源就能立刻投产。
🧩 2. 协作与智能的降维打击
最难能可贵的是,九数云补上了开源工具最大的最短板——组织协作与AI赋能。在开源工具中,你做个看板想推送到企业微信或钉钉群,也许要折腾半天Webhook。而在九数云里,深度的IM集成让数据可以在对话中流动,异常数据会自动推送到负责人的手机上,这才是数据驱动运营应有的状态。再加上其独有的九思AI辅助,你可以让AI直接帮你美化仪表板排版,甚至通过自然语言生成复杂的数据总结。
这种把复杂的数据挖掘工作交给机器,把决策的简单留给人的模式,对那些技术储备相对较弱的电商、连锁门店、餐饮等高成长型企业来说,无疑是数字化转型的超级引擎。在试遍了GitHub上那些高星主流开源BI工具后,你会明白,开源并不一定等同于性价比,真正的性价比是把昂贵的试错成本和时间成本规避掉,投入到核心业务增长中去。作为连续多年在国内BI市占率第一的帆软旗下产品,九数云提供的稳定性、强大的计算性能以及极其贴合国内业务逻辑的落地方案,在此刻显得格外厚重。作为针对高成长型企业的解决方案,你甚至可以直接上手体验九数云目前积淀的电商、零售等行业的数字化成果,提前感受业务决策的丝滑感:【九数云BI免费试用】。
🎯 七、2026年的抉择:回归业务价值的匠心
这篇文章对主流开源BI工具进行了详尽的大起底,从Superset的强大与笨重,到Metabase的极简与浅薄,再到Grafana、DataEase与Redash的偏向与局限,其用心并不在于单纯地罗列一个2025推荐榜单,而在于帮你建立一种选型肌肉记忆:在做工具筛选前,必须先看清自己团队的 DNA。你的团队是深扎SQL的工程师文化,还是更看重场景落地的业务驱动型组织?如果是后者,强行嫁接开源必然会出现排异反应。
2025年往后的数据时代,评判标准早已不是代码的开放性,而是工具能否真正融入业务流,能否让数据产生复利。当开源让你陷入无尽的维护、改 Bug 和艰难的版本升级时,不妨跳出代码的围墙,去拥抱那些真正懂业务痛点、能够提供百余平台直连且具备千万数据秒级处理能力的专业SaaS解决方案。这不仅是对技术的选择,更是对业务未来的精准托付。
## 本文相关FAQs
主流开源BI工具有哪些?2026年推荐榜单,这可能是最实在的选型指南
最近后台收到不少私信,都在问:“预算砍了,老板让搞数据可视化,有没有能打的开源方案?” 或者“搭了开源BI,数据量一上来就卡成PPT,怎么办?” 懂你们,商业智能(BI)的坑,我早年也踩过不少。说起开源BI,大家脑子里先蹦出来的肯定是 Superset、Metabase 和 Grafana,这三巨头确实占据了江湖的半壁江山。但到了2026年,这套排名逻辑变了。光看Star数已经无法反映真实的生产力,因为数据分析的战场已经从“谁图表画得花哨”转移到了“谁能帮我低成本解决ETL难题,甚至用AI直接出结论”。选工具,本质上是在为团队的未来两年买保险。下面这3个问题,是我从几百次选型撕扯中提炼出来的精华,建议你按这个脉络读下去,保证有收获。
📌 1. 2026年了,零基础团队想在局域网部署一套开源BI,求大佬分享一下真正能打的那几款?
问题描述: 哎,公司刚起步,领导给了个硬指标,必须把咱们那几个Excel台账给做成大屏,还得部署在内网。我技术底子薄,就会点SQL,网上一搜都是Superset、Metabase,但真不知道哪个上手快,别一上来就让我折腾Docker环境。有没有老法师带带路,分享下2026年的真实推荐榜单?别整虚头巴脑的概念,就要那种下班前装好,晚上就能出图的那种。
回答: 兄弟,你这需求太真实了,我刚开始带团队搞数据化那会,也是这么过来的。在2026年这个节点,如果你追求“下班前装好,晚上出图”,那传统的笨重架构确实得靠边站。我以过来人的身份拍个胸脯,给你排个路:
- 极致轻量与颜值担当:Metabase。 为啥把它排第一?因为它对非技术人员的友好度简直拉满。你只要会写SQL,甚至完全不懂SQL,用它的简单筛选模式,点一点就能出图。部署就是一个Jar包,双击运行,非常适合你这种不想折腾复杂环境的小团队。
- 可视化深度与扩展性:Apache Superset。 如果你想做酷炫的大屏,Superset 依然是天花板。但代价是部署相对复杂(依赖Python环境),而且它更偏向于懂技术的分析师。
- 破局者与“作弊器”:DataEase。 这款国产开源工具在2026年必须拥有姓名。它非常懂中国宝宝体质的管理习惯,模板化程度高,拖拽式操作,完全符合你“不想写代码”的需求。如果你的数据源主要是Excel和传统数据库,它处理起来比国外软件顺手得多。
这哥仨基本就是2026年的“铁三角”,不折腾,直接按这个梯度去试,少走弯路。
⚙️ 2. Apache ECharts 与开源BI结合,当老板要求极致的酷炫动效时,架构上怎么办?
问题描述: 我在一家中型互联网公司负责数据组,现在BI平台用的是Superset,基础图表够用,但一到年底汇报,老板就点名要那种带流向地图、3D动态柱状图的“科幻大屏”。我们都知道开源BI底层很多基于ECharts,但原生支持有限。现在正发愁,是自己写插件强行二开,还是直接换一套收费的系统?二开的话,以后的维护成本是不是个无底洞啊?
回答: 老朋友,你这个痛点戳得太准了,这就是从“能用”到“好用”甚至“惊艳”的门槛。我当年为了给老板做那个带流光特效的地图,差点没把头发薅秃。
首先,我要泼一盆冷水:在Apache Superset 这类重型开源平台上硬写ECharts插件,虽然可行,但确实是条不归路。因为BI工具的每一次大版本升级,都可能让你的自定义插件失效,很快你就会陷入“修补匠”的恶性循环。
那有没有更好的架构?我的建议是“数据驱动+轻量前端分离”。也就是:
- 后端继续用你熟悉的开源BI(如Metabase)来提供标准API数据接口,或者直接用SQL写好数据集。
- 前端单独用一套轻量级的ECharts模板库(比如DataV的React版或者自研组件),直接调API渲染。
这样做的好处是,开源BI只负责它擅长的数据处理和权限管理,不碰它不擅长的展示层。你既保住了底层的灵活和安全,又释放了前端无限的视觉创造力。架构上优雅了,你的“发量”也就保住了。如果你们团队前端资源实在紧张,连API都不想封装,那就干脆别死磕开源了,可以考虑市面上的SaaS产品。比如我们团队现在做敏捷分析,一些复杂的带权限分享的看板,直接上了九数云,它虽然不开源,但那种零代码、直接拿ECharts组件搭乐高式的体验,能让你一周搞定以前需要一个月编码的动效大屏。顺便提一句,他们内置的行业模板很强,可以直接复用,九数云BI免费试用 拿去爽一下,体验一把“降维打击”的快感。
💡 3. 轻量级SQL分析神器Metabase,如何优雅地解决权限和性能瓶颈,搭建万人级数据看板?
问题描述: 团队一直用的Metabase,当初选它就是图个快。现在惨了,公司各个部门都开始用,用户从当初的10个变成500个,卡片多了,SQL慢得不行,而且它原生的行级数据权限控制太弱了,总不能给每个销售开一个单独的看板吧?这玩意到底能不能扛住企业级的并发,还是说我们一开始就选错了,得上重型BI?
回答: 哈哈,一看到这个问题我就乐了,这是典型的“Metabase 一用就回不去了,但用着用着发现床不够长”的现象。没错,用Metabase做第一步查询分析,确实容易着迷,但遇到企业级场景,确实要有技巧。
它不是不能扛,而是你不能把它当独立数据库来直连查询。想优雅地解决:
- 性能瓶颈方面: 一定要在Metabase和你的生产库之间,引入中间层。导入模式(Caching) 是必须开的,其次,轻量级的转用ClickHouse、Doris这类分析型数据库,重量级的直接在前端挂一个Presto或Spark SQL引擎。让Metabase只做“查询编辑器”,把重活交给专业的计算引擎,它瞬间就能从老年代步车变特斯拉。
- 权限控制的“灵魂”: 你遇到的难题,根源在“数据行级隔离”。Metabase目前原生确实比较弱,这个问题绕不过去。如果你的业务逻辑极其复杂,比如“大区经理看本大区,但看不到高毛利产品”,这种深度控制,Metabase确实吃力。这时候你有两个选择:要么利用Metabase的嵌入功能,单独写一个中间层做鉴权,把数据通过参数化方式喂进去;要么,坦诚地说,如果业务逻辑就是需要极细粒度的控制,可以保留Metabase给分析师用,而面对大规模业务人员的看板,换用DataEase或走向商业化SaaS会省心很多。毕竟,工具的边界到了,硬撑只会内耗。

热门产品推荐


客户关系管理的核心在于了解客户,而 rfm指什么 则是洞察客户价值的关键。它通过量化客户的行为,帮助企业识别最有价值的客户,并制定针对性的营销策略,最终提升客户忠诚度和企业效益。
九数云 | | 2025-09-19
财务报表是企业财务管理中非常重要的一部分,今天教你快速学会财务报表如何做
九数云 | | 2023-06-02
报表工具平台是用于创建、管理和分发报表的软件系统。它们帮助企业将原始数据转化为有意义的可视化信息,从而支持决策制定。一个好的报表平台应该具备数据连接、报表设计、数据可视化和权限管理等功能,以满足不同用户的需求。选择合适的报表工具对企业至关重要,直接影响数据分析的效率和质量。
九数云 | | 2025-12-26
报表生成系统是一种强大的工具,它能够帮助企业从各种数据源中提取、整理和呈现信息,最终以报表的形式展现出来。通过使用报表生成系统,企业能够更有效地进行数据分析,从而支持决策制定,优化运营效率。这类系统通常具备数据整合、报表设计、数据分析与可视化、安全与权限管理以及共享与分发等核心功能,满足企业对数据管理和利用的多元化需求。
九数云 | | 2025-12-23
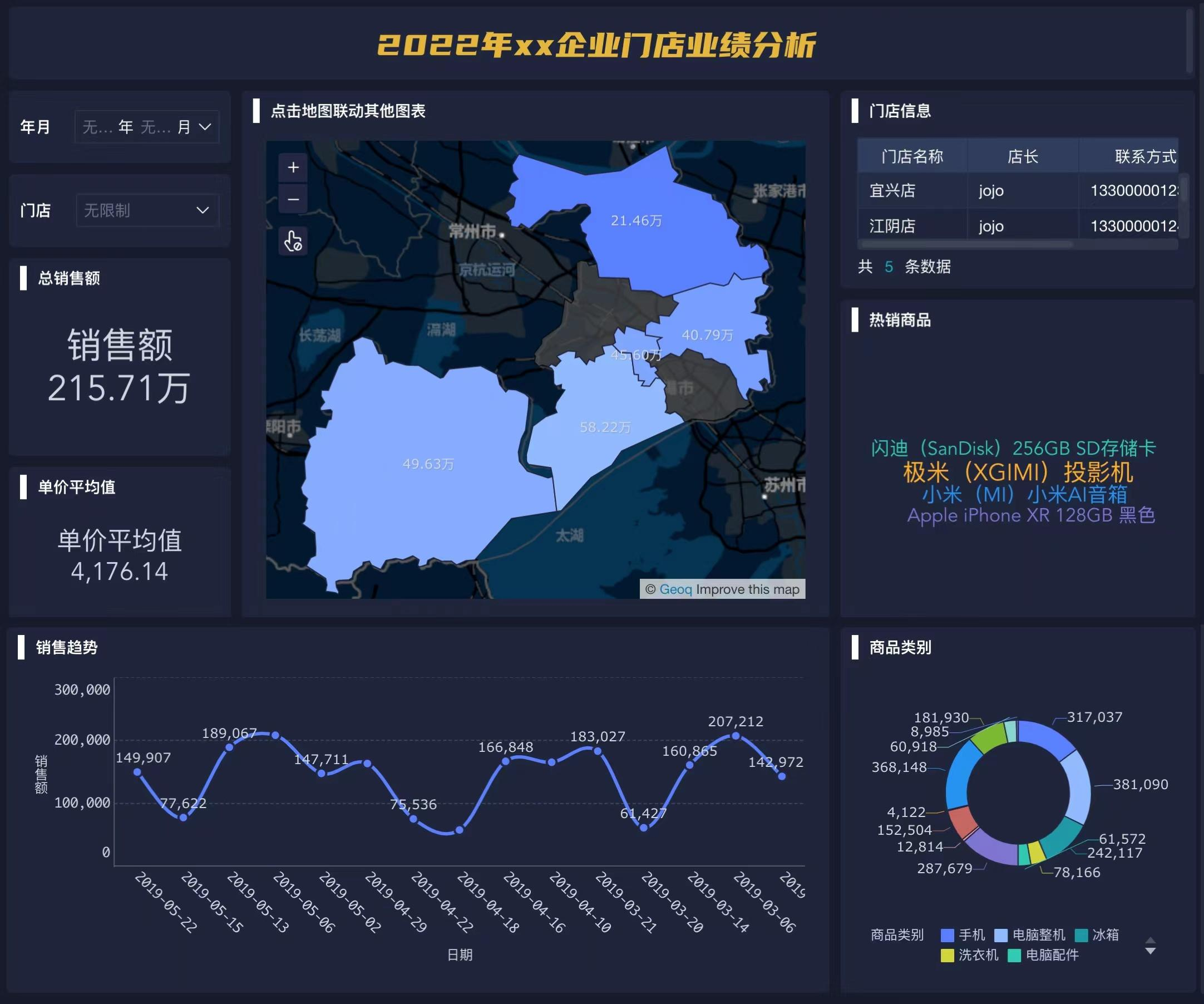
每到年末,企业都面临着一项重要的任务:制作年度报表。这份报表不仅是对过去一年经营成果的总结,更是企业决策的重要依据。但是,对于许多财务人员来说,年度报表怎么做仍然是一个让人头疼的问题。本文将深入解析年度报表的制作流程和关键要点,助您轻松掌握这项必备技能。
九数云 | | 2025-09-03
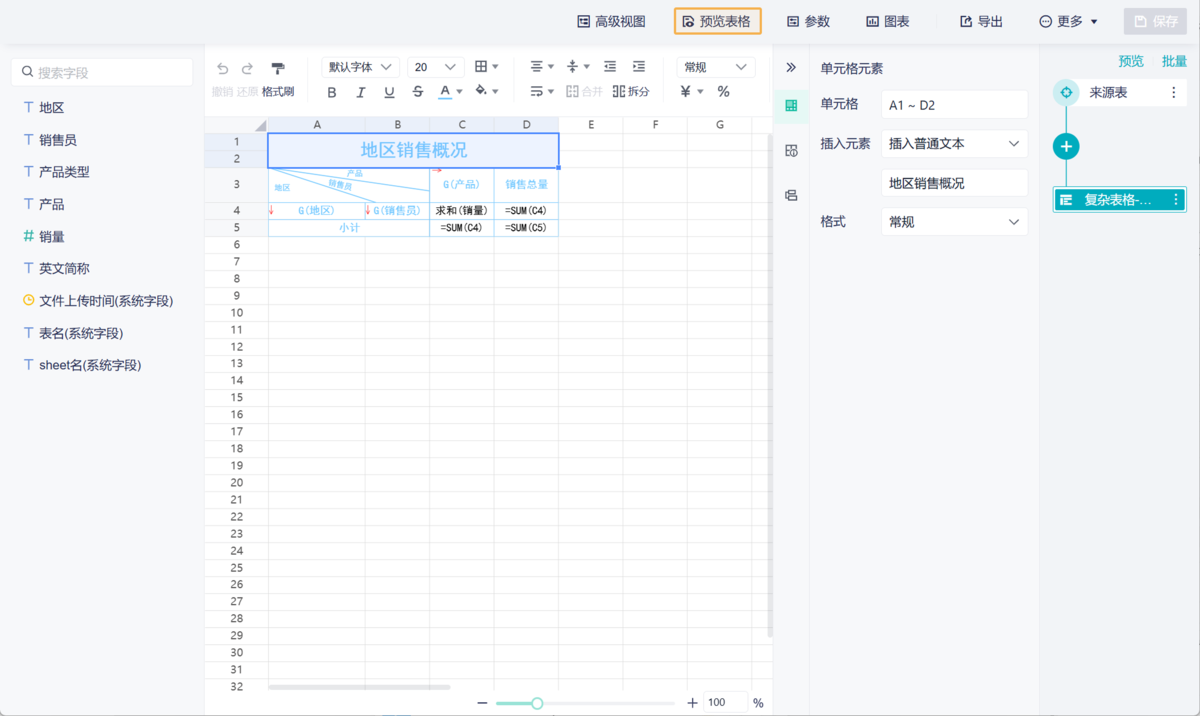
在当今这个数据驱动的时代,企业对于数据分析的需求日益增长。然而,面对海量且复杂的数据,如何高效地提取有价值的信息,成为了许多企业面临的难题。多维度表格作为一种强大的数据分析工具,正被越来越多的企业所采用。它能够帮助用户从多个维度审视数据,发现隐藏在数据背后的规律,从而提升数据分析的效率和质量。
九数云 | | 2025-09-17